Which Starbucks offer makes the most profit?

Introduction
At regular intervals, Starbucks sends an offer to users of the mobile application. This can be a simple advertisement for a drink or an actual offer such as a discount or BOGO (buy one get one free) or an informative offer with product information. Some users may not receive offers during certain weeks. In this way, Starbucks can probably increase the likelihood that the customer will open the offer after receiving it and complete the transaction. We will try to understand which offer brings the most profit. At the same time, we will try to maximise Starbucks’ profits by analysing which variables may be most important in creating profit.
To see more details on the analysis, you can find my Github link here.
Project Goal
Based on the context above, this project will try to ask the questions below
- What are the main factors influencing the customer’s use of the offer? Should the company send the offer or not?
- Is there an offer that outperforms the others in terms of profit?
Data Dictionary
The data is contained in three files:
- portfolio.json — containing offer ids and meta data about each offer (duration, type, etc.)
- profile.json — demographic data for each customer
- transcript.json — records for transactions, offers received, offers viewed, and offers completed
Here is the schema and explanation of each variable in the files:
portfolio.json
- id (string) — offer id
- offer_type (string) — type of offer ie BOGO, discount, informational
- difficulty (int) — minimum required spend to complete an offer
- reward (int) — reward given for completing an offer
- duration (int) — time for offer to be open, in days
- channels (list of strings)
profile.json
- age (int) — age of the customer
- became_member_on (int) — date when customer created an app account
- gender (str) — gender of the customer (note some entries contain ‘O’ for other rather than M or F)
- id (str) — customer id
- income (float) — customer’s income
transcript.json
- event (str) — record description (ie transaction, offer received, offer viewed, etc.)
- person (str) — customer id
- time (int) — time in hours since start of test. The data begins at time t=0
- value — (dict of strings) — either an offer id or transaction amount depending on the record
Data Exploration
In order to understand the data, we will explore the three databases.



In the first instance, we will focus on the profile database.
We can notice a thing, there are some missing values for three variables:

We can see that the same individuals have missing values for both income, gender and age:

We are going to try to estimate these values. So, we have to create new variables, in order to predict well these missing values.
Data Preprocessing
We will create variables to track whether an offer was a success, a failure, or whether the person tried to use the offer. We will base this on the time taken to receive, view and complete the offer.
For instance, when an offer is successful, it means that time received is lower than time viewed which is lower than time completed which is lower than time expiry.
Then we aggregate the customers and the types of offers to have a table that summarises the number of successful offers and the number of unsuccessful offers.

Then we group the database by type of offer (Bogo, Discount, Informational).
We create variables for each type of offer. We create, for example, total offer, total successful offer, total spent, total spent per offer.

After that, we come to the missing value prediction phase. We have chosen to use the same procedure for the three variables with missing values.
Three separate models were created, one model for each of the missing attributes: age, income and gender. The portion of the profile dataset without missing values would be used to train the models (approximately 87.2% of the profile data).
Both the age and income models are regression problems, while the gender model is a multi-class classification problem. K-Fold cross validation with 5 folds was used in the grid search process to optimize the models.
XGBRegressor and XGBClassifier are the models chosen for the regression and classification tasks respectively. These are tree-based non-linear models that are relatively fast and accurate.
Predict Age:

We can see that the model is not perfect, because the predicted ages are generally off by approximately 16.5 years. However, given the few variables at the start, the result is not so bad.
Predict Income:

We can see that the model is not perfect, because the predicted incomes are generally off by approximately 14,510 dollars. However, given the few variables at the start, the result is not so bad.
Predict Gender:
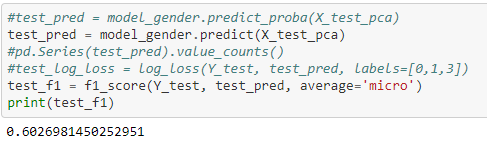

We can see that the model is not perfect, because the predicted genders are generally Male (almost 90%). However, given the few variables at the start, the result is not so bad, but we can ask ourselves if the low representation of women in the starting base is not the cause of this.
To see more details on the analysis, you can find my Github link here.
EDA (Exploratory Data Analytics)
With the data filled in, we can now analyse the database further.


There are few people with less than 40 years old, and in the same time, the income is often greater than 40,000.

We can see that there are not a big difference in the offer type distribution. We can just notice that the discount offer seem to be more successful.

The distribution gender is the same for all the offers.
The three offers seem to have the same income distribution.

The three offers seem to have the same age distribution.

The bogo offer seems to have clients who don’t want to spent a lot of money.
Then we decided to create a profit variable. In order to create it, we started by creating a cost variable. This variable is calculated simply by multiplying the number of offers with the reward the customer gets. Then, to create the profit variable, we subtract the cost from the total spent by the customer.

We can notice that men bring small profits (even if there are big outliers) in comparaison with women.

The discount offers are more probe to generate bigger profit than bogo offers.

The bogo offers are more risky, their costs are bigger than others. It may seem interesting because one thing to do to make more profit is to reduce cost.
To see more details on the analysis, you can find my Github link here.
Model
We want to create two different models. A Bogo model and a Discount model.
Model Bogo
We start by creating a Bogo model with all available variables. Our variable to explain is profit.

The r-squered is very high. We don’t need to test another model than this Forest Regression model.

Unfortunately, one variable explains almost all the variance. It was pretty obvious that the total money spent would explain the profit almost perfectly.
We therefore decide to remove the variables directly related to the offers made or the money spent.

The r-squared score is not perfect, but it’s normal without some important features.

We can see that the income of client is important, and the number of offers. It seems probably that Starbucks should target the high income clients, and don’t hesitate to make many offers.
Model Discount

As bogo model, the r-squared score is very high (too high).

Il se passe exactement la même chose que pour l’offre Bogo. One variable explains almost all the variance. It was pretty obvious that the total money spent would explain the profit almost perfectly.
We therefore decide again to remove the variables directly related to the offers made or the money spent.

The r-squared score is better than bogo model. 0.59 is pretty good.


As bogo model, we can see that the income of client is important, and the number of offers. It seems probably that Starbucks should target the high income clients, and don’t hesitate to make many offers.
So we have models that allow us to know whether to send the offer to certain customers or not. And on top of that, we know which variables are important in order to make a profit.
But there is something we do not know: does the type of offer play an important role in making profits?
Model profit
We will create variable to find out if the offer type is important to make profit.
We create a binary variable to see if a offer has had a “big” profit (higher than 15).

We create two binary variables that say whether the offer type is discount or bogo.

We decide to test several models to compare the accuracy of each.

We decide to compare the best features for the logistic regression and for SVC, because the results are very close.


We can see income of clients and cost of offers are very important. We can notice the offer_type_bogo is lower in the ranking, but ahead of discount offer. It could be a good indication to show off that bogo is better than discount offer. Maybe, it’s too obvious again that the variable cost for exemple is very related to the variable profit.
Conclusion
We try an another model without the variables directly related to the offers.
We keep this model, because it allows us to compare with the previous model, and in addiction the prediction accuracy is very good.

We can notice than the age and the fact that the offer is mobile are important features. What’s more, we can notice discount and bogo are very low in the ranking. We can not conclude in favor of bogo offer.

We can see on the graph, bogo offers are more likely to allow small profits in comparaison with discount, but the number of profit offers is more important for discount offer.
Improvements
I managed to get a good understanding of the data. Unfortunately, I was not able to find out which offer was the best. Maybe focus on the different Bogo offers and the different Discount offers to bring out the differences. Also, maybe working on the seasonality of the offers can help to make it clearer.
To see more details on the analysis, you can find my Github link here.
